
Progress in LLMs
Parameter Size isn't Everything
January 3, 2026
It used to be that machine learning models were evaluated by seeing how well they performed on datasets. MNSIT is an example a dataset containing 60.000 images of handwritten digits, that was used to train machine learnign models on character recognition. Because the MNIST dataset contained a large number of both easy to recognise hand written numbers, and very difficult to read ones, it was a very good benchmark. Even very good charcter recognition models would struggle withthe most difficult to read handwritten digits. Because of that (and because progress in machine learning went a lot slower in the past), it took over 20 years after the dataset was created before models got so good they would all scored 99.9% on the benchmark dataset, and the MNIST dataset gradually became useless as a benchmark when comparing the quality of the latest character recognition models.
Between 2018 an 2026, the development in LLMs has progressed so fast that it is difficult to compare models from 2018 with the later models from 2022, or 2026. Models from 2018–2019 (GPT-1, BERT, GPT-2) were evaluated usng benchmarks like GLUE, containing lots of example sentences that were usually followed by a yes/no style question about the earlier sentences. For example: 'do both sentences mean the same thing', 'are these sentences gramatically correct', 'does this sentence convey a positive or negative sentiment', etc. This way, researchers had a reliable method to score how well an LLM performed on its
But within 12 months after the GLUE benchmark hd been created, all of the new models would practially answer almost all of the questions correct, and became useless when scoring newer models. For SuperGLUE this took 2 years. This pattern has only intensified. Hugging Face opened LLM Leaderboard v1 (in June 2023) that combined different new benchmarks (ARC, HellaSwag, MMLU, TruthfulQA, WinoGrande, GSM8K) into a score that would allow people to compare the different LLMs. But the project was retired by June 2024 because all six benchmarks were approaching their ceiling.
Increasing Model Size
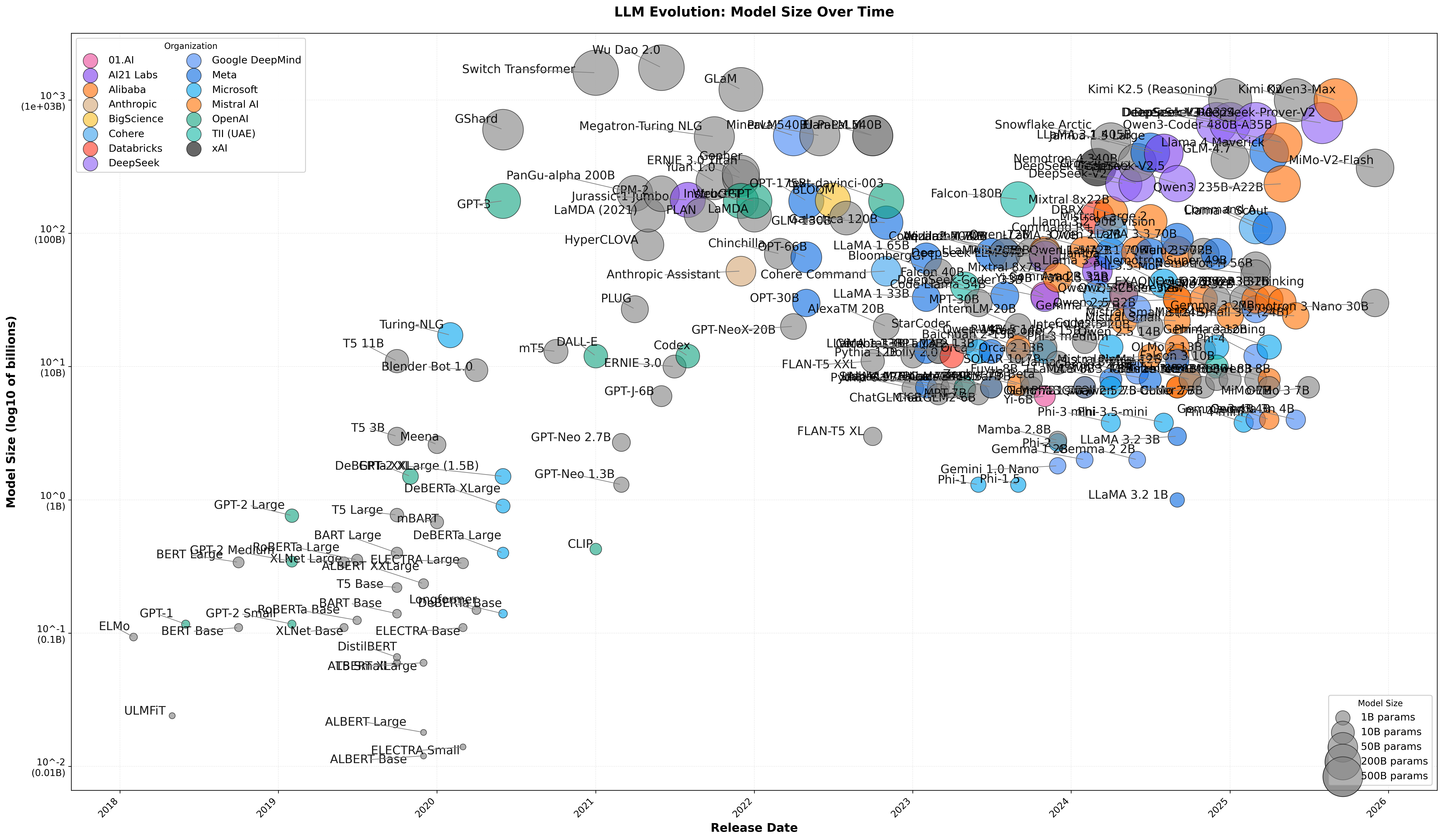
The size of Large Language Models (LLMs) has grown over 100x over just a few years. Generally, when we talk about the 'size' of these models, we mean the number of parameters. These parameters are adjustable numerical values, like knobs that get fine-tuned during training to encode patterns in language and knowledge into the model. More parameters allow the model to learn more intricate patterns and perform more sophisticated reasoning.
After the initial success of scaling LLMs to the size of GPT-2 (released in February 2019) with 1.5 billion parameters (and still small enough to fit on a thumb drive), proponents of the scaling approach argued we were witnessing the emergence of something transformative, and that simply scaling LLMs could perhaps even pave a path toward artificial general intelligence (AGI). There was a rapid push to even larger LLMs, bringing us quickly to models like to GPT-3 (released in June 2020) with 175 billion parameters, that now required roughly 350 GB of memory. Scaling the number of parameters, and training these models on exponentially larger datasets has certainly been one of the advances that has led to increasingly impressive capabilities.
Simply increasing the number of parameters alone doesn't necessarily result in a better model. How well a model will perform depends on a lot of additinoal details: the training data used, the trainig proces, as well as on important parts of the architecture like the context window.
Researchers were quick to see that scaling only the number of parameters would turn into a road with diminishing returns around 2022. For one, there was only a limited amount of written text available on the entire internet, and further scaling the number of parameters without having access to large amounts of additional (and better quality data) might not be the most productive way forward. Despite these limitations, the ongoing research has continued to make vast amounts of progress. Especially after 2023 the story has become more nuanced than simply scaling the number of parameters in a Large Language Model, which on its own is no longer the main driver behind the ongoing progress.
Rather than training ever-larger models, many researchers have focussed over the past years on optimising different parts of the LLM architecture (especially the size of the 'context windows') up to 1000x. This has made it possible to improve the output quality from these models significantly, irregardless of the number of parameters. Optimising many aspects of the architecture has increased the efficiency, causing the cost of running these models to go down, which then made it possible to build new 'layers' on top of these optimised models.
The most effective of these 'new layers' turned out to be combinations of reasoning, and tool-use. These innovations have helped to 'tame' the hallucinations that LLMs inherently suffer from, and allowed us to force their responses into more usable outputs. We will examine these technical improvements in more detail below. It is the combination of all of this together that has created way more progrss over 2022-2026 than many people thought would be possible based on simply scaling the number of parameters in the LLMs alone.
The most impactful of these innovations has been: (1) "reasoning models', that break complex tasks into steps, verify their work, and course-correct when needed, potentially mitigating the drift-to-error problem that LeCun identifies. (2) agentic systems that use language models to reason, but are supplement with additional tools they can use to search for information, execute code on a computer, and interact with external systems. And (3) tying thse agents together into larger networks where multiple specialized agents collaborate, delegate tasks to one another, and combine their outputs to solve problems no single LLM could handle alone.
As infrastructure optimization was driving down compute costs, it became feasible to let these models generate longer outputs, and perform internal 'Chain-of-Thought' (CoT) reasoning: running multiple (internal) steps where the model restructures the user's input, breaks it down into intermediate steps, and goes over each step in detail, before producing a final answer. And finally, letting these models respond with structured outputs that enabled them to interact with and use external tools.