
Transformers
from Encoders to Latent Spaces
February 19, 2025
Data Compression before Problem Solving
The data we feed into a neural network during training (for example images, or human language) might not be stored in the most useful format for a neural network to extract usable structures from it.
As an example, think about human language. For a computer it is not very useful to receive text as a series of raw characters. In order to perform calculations, we want to represent natural language as numbers that capture something about the meaning of words.
The approach of training neural network will often work much better when we first transform the data into some form that is more suited for a machine to work with.
Encoder + Decoder
Instead of relying on lots of human thought and research to design compression schemes by hand, the idea behind autoencoders is to use neural networks to learn the most useful representations directly from a dataset [Cho et al., 2014]. The key insight is data-learned compression: learn the best way to compress the data from the data itself.
This is enormously useful when working with structures we don't have a deterministic, hardcoded understanding of, like language or images.
The basic idea is very elegant: we train two neural networks together at the same time:
- An encoder that maps the input into a compressed representation
- A decoder that reconstructs the original input from the compressed representation
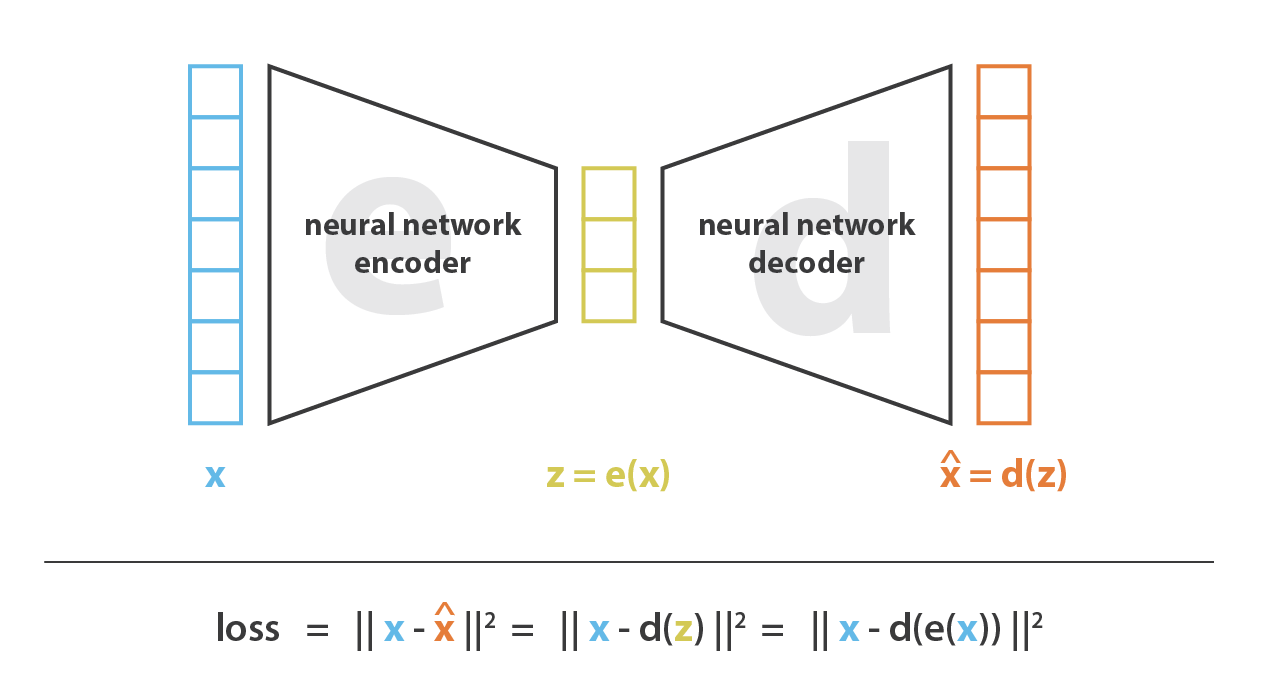
Note how we are training both the 'encoder' as well as the 'decoder' together, as two parts of one larger neural network. By requiring the original input data to be reconstructed as accurately as possible (after it comes out of the combined encoder-decoder), we are forcing the original data to be compressed so that it can go through the narrow bottleneck bottleneck. But we are demanding our encoder to compress the data as accurately as possible during the training. So that the decoder than reconstruct the complete original input data again as accurately as possible form the encoded version of the data.
Minimizing the reconstruction loss ensures that the most important features survive the compression, and lets the whole setup train both an encoder and a decoder in an unsupervised way, without us needing to label any data.
The compressed data as it comes out of the encoder (in the bottleneck) is now compressed in such a way that we preserve the most important features (so that the decoder can still reconstruct the orignal input as accurately as possible). This compressed representatino is also often called the latent representation: the most optimal compression that an encoder + decoder network of a particular size and with a specific architecture has learned for a given dataset of a certain size.
Translation
One of the more astonishing things about the encoder-decoder approach is how naturally it generalises to all sorts of applications.
The most famous early application was machine translation. In rough terms: if you train an autoencoder on English text, you get an encoder that can compress English into a compact representation. If you then train another on French text, you get the same for French.
Instead of training a network that tries to translate English directly into French, we have simplified the problem considerably when using autoencoders to create compressed representations of our data. We now only need to train the part that maps compressed English into compressed French. The individual encoder and decoders handle the rest.
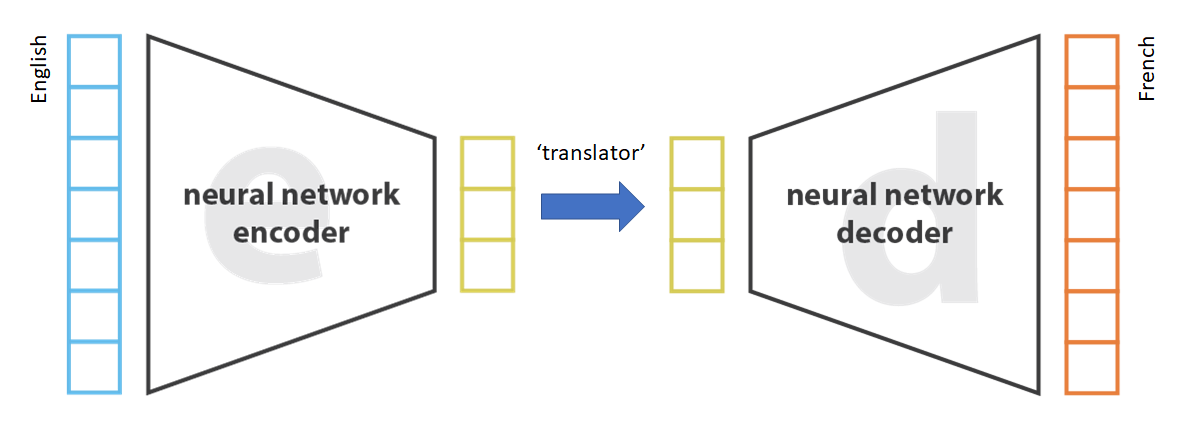
This separation: encode into a compact representation, translate there, then decode, is the core idea behind all the transformer-based translation systems that followed. We will dive into more detail in this in the next sections