
Transformers
Introduction
May 10, 2025
Transforming and Translating Data
One of the most remarkable breakthroughs in machine learning over the past decades, have come from applying neural networks to highly complex data like human language and images.
To a computer, an image is just a large grid of pixel values. Similarly, human language is initially represented as a sequence of letters, words, or tokens whose meaning depends heavily on context, ambiguity, tone, and prior knowledge. What we recognise as faces, objects, concepts, and ideas is present in the data, but implicitly. This is what makes these concepts so difficult to describe mathematically or encode manually.
A grid of pixel values that forms an image of a dog, for example, contains completely different numbers when the dog is viewed from different angles, in different lighting conditions, and against different backgrounds, yet we still recognise it as the same kind of object. Describing that recognition process in exact mathematical rules would be almost impossible.
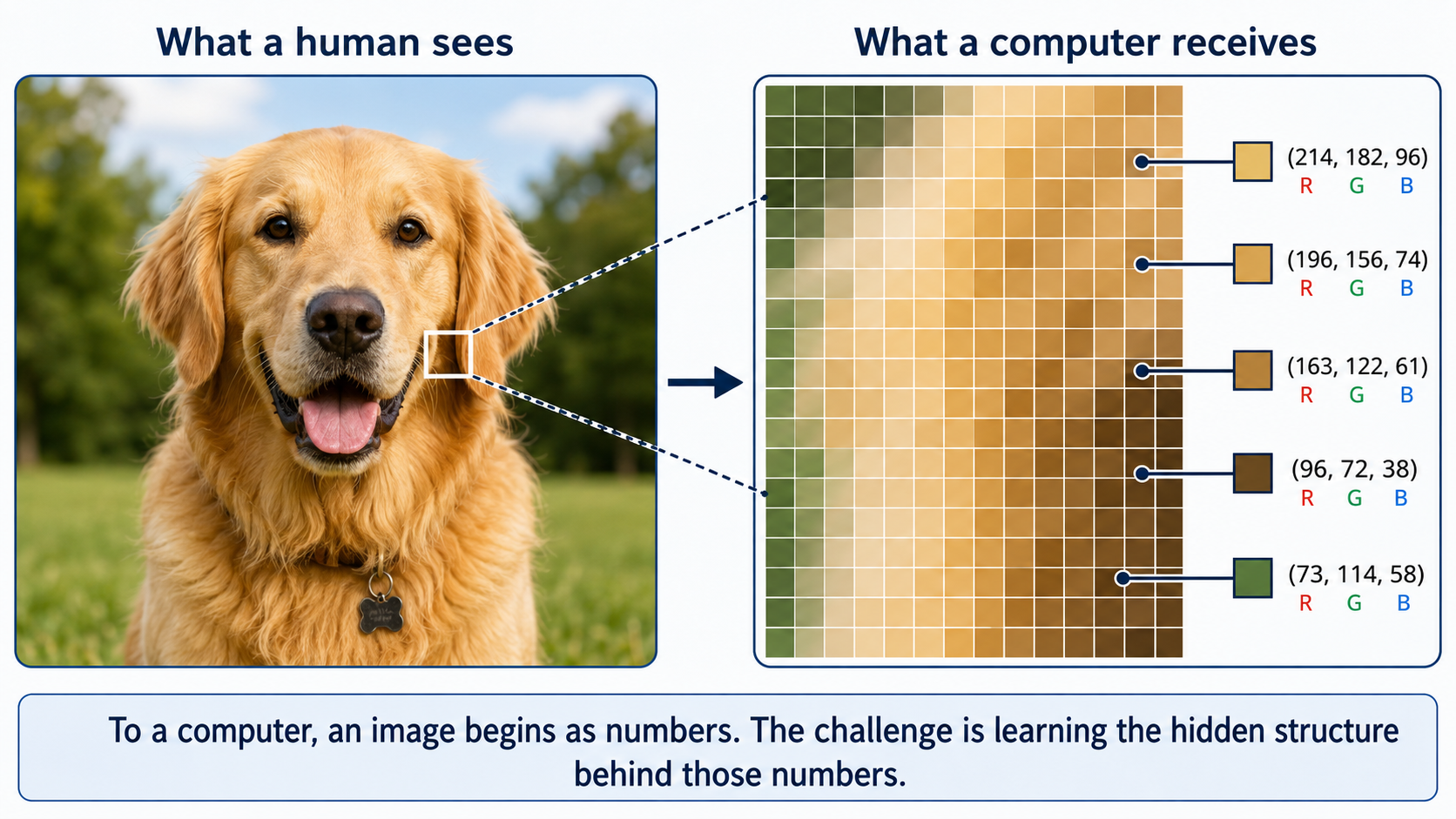
Neural networks have been so powerful because they can learn to recognise these implicit patterns directly from raw data. By combining clever techniques with vast amounts of data and computing power, researchers have achieved extraordinary progress in teaching machines to learn abstract representations of these conecepts (faces, objects, concepts, ideas).
This is the central idea behind representation learning. Instead of asking humans to define every concepts such as “face”, “object”, or “meaning” in terms of raw pixels or individual letters, we train neural networks to organise themselves. So that different layers of the network learn to capture increasingly abstracted versions of these concepts.
In an image model, early layers detect edges, textures, or colours, while deeper layers learn how to combine these features and recognise more meaningful structures like shapes, objects, and faces, while even deeper layers learn how to recognise whole scenes. Language models work in a similar way, learning to recognise linguistic rather than visual patterns. Early layers may capture relationships between letters, tokens, and words, including word forms, syntax, and common grammatical structures. Deeper layers can then combine these into representations of phrases, sentences, concepts, and broader relationships between ideas.
As information passes through the network, different layers learn to capture increasingly meaningful abstractions.
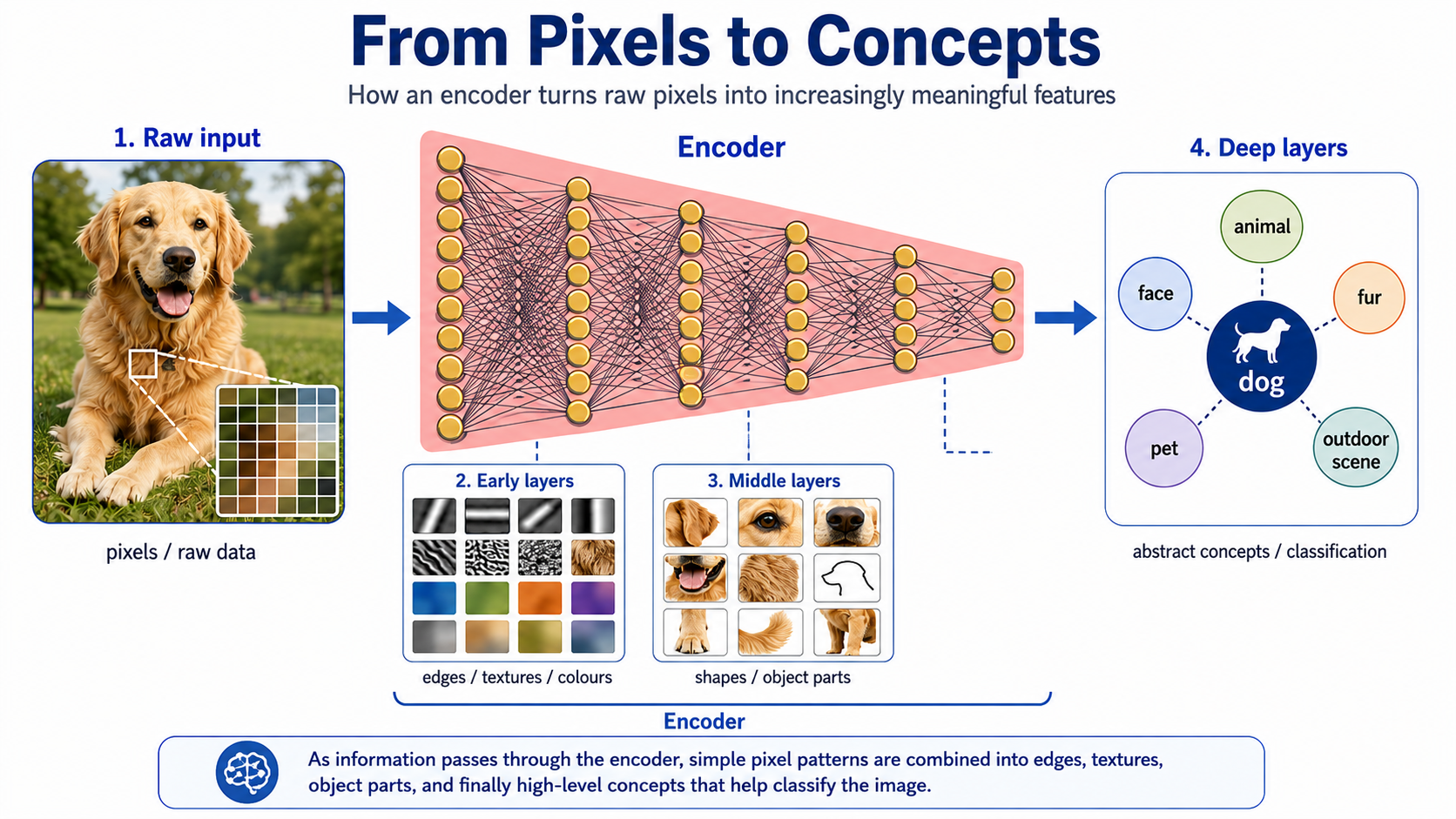
These learned representations can then be used for many tasks, such as recognising objects, classifying images, translating languages, generating text, or answering questions. In the following sections we will explain in more technical detail how this works:
Many advanced AI systems can be understood as having three broad parts: an encoder, a transformation step, and a decoder.
The encoder takes raw input data (like text, audio, or images) and converts it into an abstract representation. This representation is often easier for the computer to work with than the original pixels, words, or sounds, because it captures the most useful structure in the data. We will then see how this enables an explosion of various applications
By combining clever techniques to restructure and compress data (such as autoencoders, attention mechanisms, and transformers), researchers have achieved extraordinary progress in the quality of these encoders. We will examine in more detail how these encoders are build and trained, and what the compressed representation of the data typically looks like. And ongoing research that is trying to further improve the quality of these encoders.
Once the data has been encoded, the model can perform operations on this compressed representation of the data.
Finally, a decoder turns the internal representation back into an output: a generated image, an audio file, or a piece of text.
In this sense, many AI systems that transform one modality into another (like text-to-speech, image-to-text, text-to-video) are performing a kind of translation. Whether translating French to English, converting a text description into an image, or turning speech into text, we are always learning a mapping from one representation to another when we are working on translation, text-to-speech, text-to-image, and other modalities, that all essentially translate.
This perspective will guide the rest of this section. We will first examine how encoders build useful internal representations, then look at how attention and transformers improve those representations, and finally see how encoder-decoder systems make it possible to build models that translate, generate, and transform data across many different modalities.
Each of these ideas builds on the previous one, and together they explain much of why AI capabilities advanced so dramatically from 2017 onwards.