
Transformers
Latent Spaces and Embeddings
February 19, 2025
Latent Spaces
After training an encoder on a large dataset, each input gets mapped to a list of numbers - a vector. A word like "king" might be represented by several numbers: [0.71, -0.32, 0.58, 0.11, ...]. We can think of each number as a coordinate, and together they place that word at a specific point in a high-dimensional space. That space is called the latent space. The specific point that a particular input gets mapped to — its coordinates in the latent space — is called its embedding in the latent space.
This becomes very interesting when the encoder has learned a very good and useful compression. In such a case, there is more to the latent space than just a collection of points, with each word being mapped to a different point in this space. The geometry of the latent space becomes meaningful as well: semantically similar inputs will be placed nearby, and the relationships between concepts might be represented by directions and distances in the space.
Word Embeddings
The clearest illustration of this comes from word embeddings in natural language.
When we train an encoder on a large corpus of text, it learns to map each word in our vocabulary to a vector. The network is trained such that words that appear frequently in similar contexts end up with similar vectors.
The result looks something like this (here shown in a simplified 2D representation):
- "king" and "queen" end up close together
- "man", "woman", "boy", "girl" form a nearby cluster
- "dog" and "cat" sit near each other, far away from the royalty words
This makes intuitive sense. "King" and "queen" frequently appear near the same words — throne, crown, rule, palace — so the network pulls them together in the latent space. The network was never told they were related; it inferred this from patterns in text.
The Geometry of Meaning
The really striking thing about word embeddings is not just that similar words are nearby — it's that the directions in the space are meaningful too.
Consider the vectors for "man", "woman", "king", and "queen". If you compute:
king − man + woman ≈ queen
This works. The difference between "king" and "man" is roughly the same vector as the difference between "queen" and "woman". There is a gender direction in the latent space — a consistent geometric axis along which male and female concepts are separated.
The same kind of structure appears across many different relationships:
`Paris − France + Germany` ≈ `Berlin`
or
`walked − walk + run` ≈ `ran`
The network was never told about gender, royalty, geography, or verb tense. But the encoder inferred all of these as consistent geometric structure, purely from patterns of word co-occurrence in text.
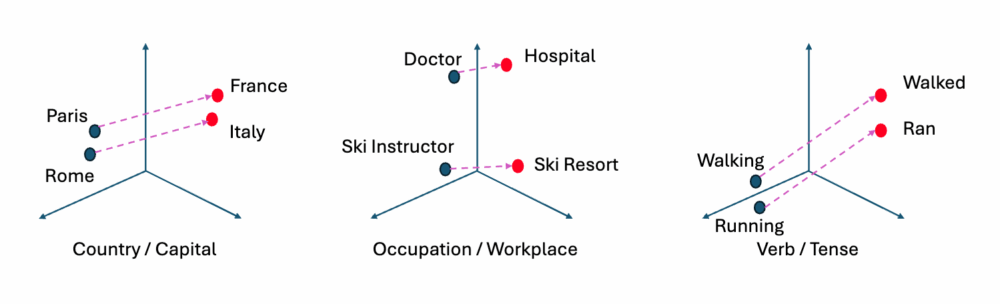
What This Tells Us About Latent Spaces
The word latent (from the Latin latere) means "hidden". In statistics and machine learning, a 'latent variable' is one that is not directly observed but inferred. A good latent space is a geometric encoding or geometric representation of the (hidden) structures stored in the data.
- Distance should encode similarity: nearby points correspond to similar concepts
- Direction should correspond to conceptual dimensions like 'gender', 'tense', or 'geography'
- Orthogonal axes should ideally correspond to independent concepts
- Arithmetic in the latent space should ideally corresponds to operations on the concepts themselves
This is what makes a well-constructed latent spaces so powerful. Once you manage to train an encoder on loads of data that gives you a good latent representation of the data it encodes, you can search for similar items by finding nearby points, interpolate smoothly between concepts, and generalize to new combinations by composing directions.
We are saying 'should' make a 'well-constructed' latent space very pwoerful, because in practice these criterea are not always met. We will see in more detail in the next sections that independent concepts are not always mapped to orthogonal direction in latent space, how slightly different versions of a similar concept might in practice not map to nearby points in the latent space. Ideally we get latent spaces where specific operations on the points in the space correspond to certain conceptual manipulations to the concept (like in the above image). But in reality it never works this smooth
The latent space representation is learned by the encoder. And the result of the training process is unfortunately often something that is more noisy and distorted than what we are describing here. Often general broad concepts like 'gender' or 'tense' might correspond to clearly defined directions, but things often stop being this well-defined when we study more subtle concepts in the latent space.
Improving the methods that are used to train encoders (and to turn data into latent space representations in a self-supervised way) so that the structure of the resulting latent space is as rich and consistent as possible is part of active and ongoing Machine Learning research.