
Generating New Knowledge with LLMs
The Limits of LLM Based Systems
February 27, 2026
When thinking about LLMs, how they work, what it is that they learn, I came up with the following set of analogies that I hope help to think about these ideas:
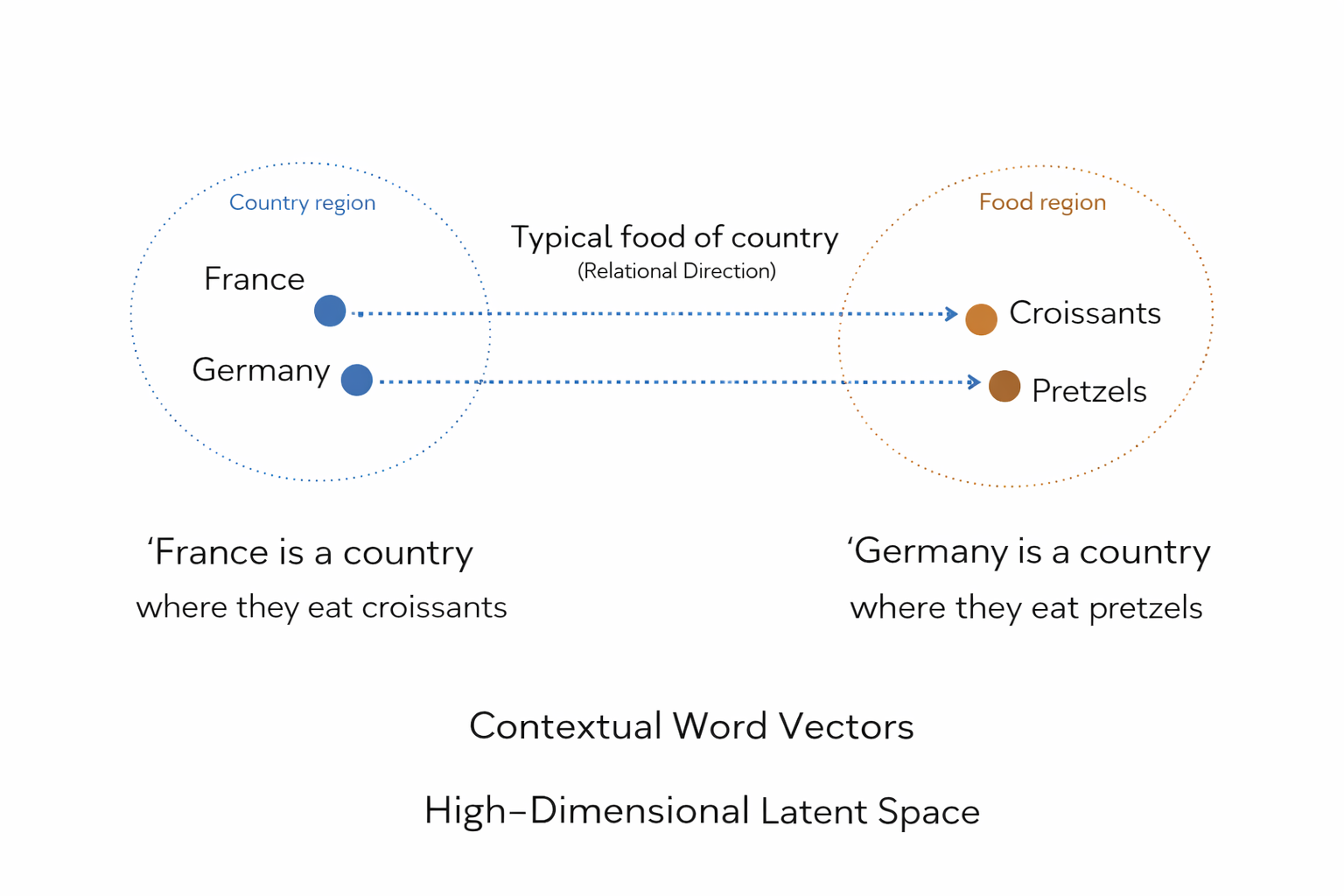
In machine learning we do not work with words directly, but we create an 'encoder' that transforms words into vectors in an embedding space. Every word (or more accurately, every token, given its context) gets turned into a list of numbers, that we can think of as a point in this higher dimensional 'embedding space'.
Latent Space Representations of Knowlegde
'Knowledge statements' typically don't involve one token or word, but are relationships between many words. Let's try to think about the space of 'knowledge statements' as relations between different points in this latent space.
Eeach point in latent space representing a certain word in a certain context. And we can visualise statements as graphs that encode relationships between the different words that make up the statement.
For example, when an LLM is presented with a series of statements, understanding how each of these statements relates to another description of the same object but in terms of different jargon, requires an LLM to accurately translate each statement (a graph between point in latent space) into a different graph between other points in latent space (describing the same thing in terms of other words).
We can think of the 'knowledge' that the LLM has learned as a having learned reliable paths or maps between these these different graph objects in latent space, that allow it to maintain coherent and correct output. [3]
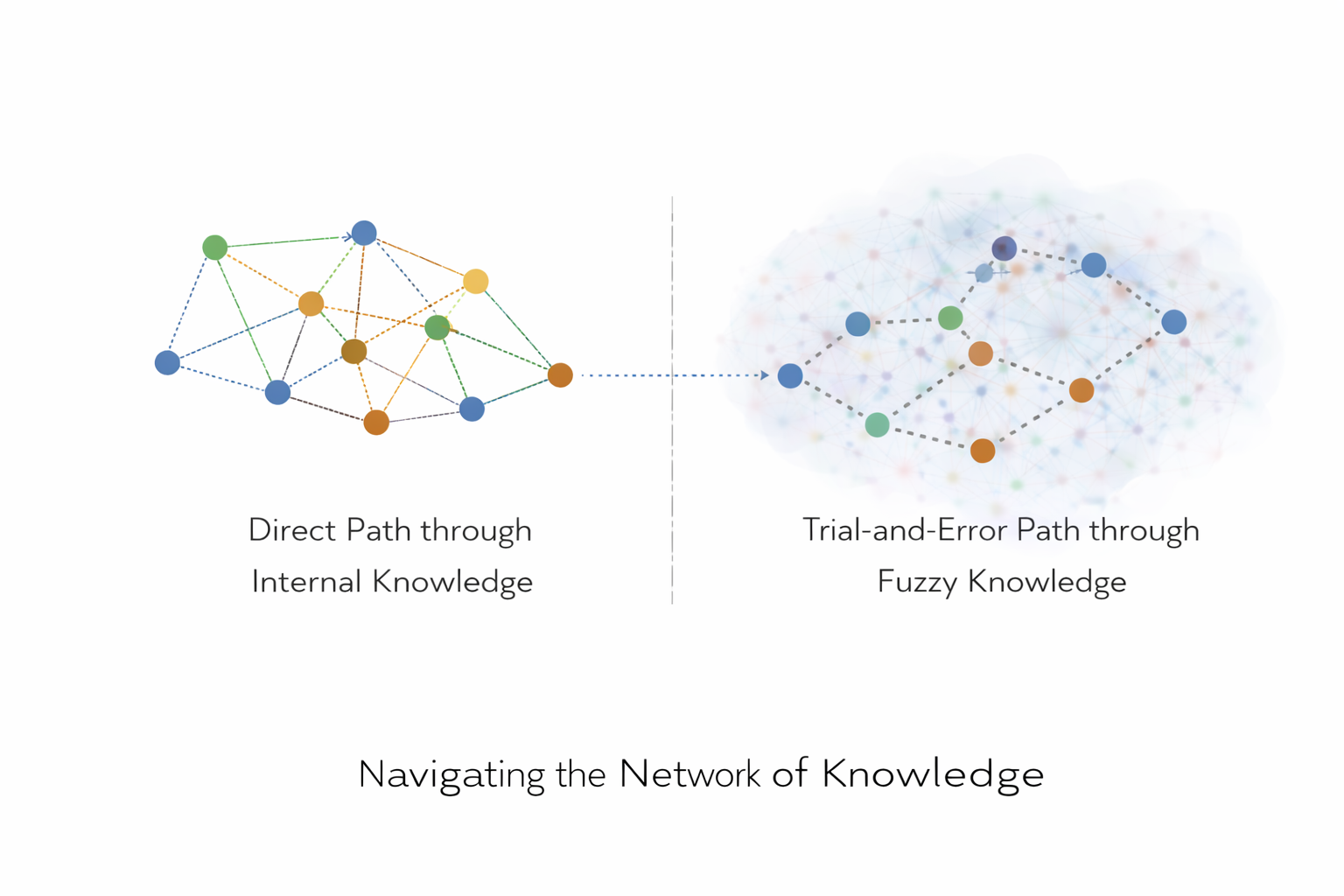
Knowledge as a Subset of All Possible Statements
There many possible statements and relationships possible between all objects. Let's think of ALL these possible statements and relationships between points in latent space as a whole cloud of different graph relationships between statements. So many different graph relationships that they fill up a cloud in the latent space.
But not all of the statements in this fuzzy volume are correct. There is only a small subsection of relationships that are factually accurate, represent verifiable properties of the observable world, and are internally coherent with other relationships between other statements.
This much smaller 'grid' or 'network' of relationships between objects that are 'correct', 'verifiable', and 'internally consistent', among the much bigger space of all possible statements is what we try to train the LLM on. When the model 'knows' some of these relationships, it can reliable take the learned routes of this network as shortcuts through the latent space. [1]

When a model does not yet know these shortcuts, it either is completely unaware of them, or it has learned a rought statistical reflection of a relationship, that may be accurate in some cases, but lacks the sophistication to be accurate all the time
Note that not every node (every conclusion) is reachable from any given start point. One striking illustration of this: when training an LLM that "A is B", it fails to infer "B is A". [2]
Nevertheless, if a model is unaware of some knowledge, it can still try to navigate an accurate path through knowledge space by trying to combine multiple statements that it is aware of, and see if combining them still allows the model to accurately walk along the graph to the final statement that it is trying to reach.
Knowledge Preservation
It would be very nice if we could define some formal notion how much 'knowledge' is contained in a piece of text, or statistical model. And check if the knowledge decribed in the LLM input + the knowledge that the model has aquired during training = preserved in the output.
But for now, let's not get stuck on this. It might very well be that LLMs work in a much more statistical and less predicatable way that doesn't preserve such a notion of knowledge. Keep in mind that LLMs work statistically.
The Value of Software in the Future
With all of the Agentic AI developments, there is a lot of talk about all apps going to disappear in the future, and users only talking to an AI tht can build any app on the stop.
Though this might be theoretically feasable, I don't think it will be practicle. It will not be practical for the same reasons that existing software developers do not do this either.
Often, when working on a detailed problem, it is more efficient to outsource part of the problem, than to rediscover everything by yourself, which might be prone to errors and inefficiencies. It is more efficient to use an existing SDK, and take a direct shortcut through this space of knowledge, than tryig to arrive at the same point yourself. The price that an SDK charges (when it is a paid one) can be seen as fee, or a toll to use their particular shortcut through 'knowledge space'.
If anything, I suspect that the demand for custom libraries and packages that solve niche solutions might only increase in the future, as the amount of (Ai assisted) software development will only increase as well.
The Limits of a Single Super-AI
When we have build an AI agent that is capable of using toold, by relying on an LLM that has been trained on a large set of data. Can we use this Agnt/LLM to describe/discover new facts outside of the 'knowledge network' that it derived from its training process?
I think this will be difficult. As I tried to explain in an erlier post on this blog, because an LLM is trained on relationships between language, it might struggle to develop the kind of historical paradigm shifts that have played a major role in the development of the history of science.
A single LLM might at best reach new knowledge facts that are located just outside the boundary of the knowledge network that it derived from it's training data. Expanding beyond that might be possible, but certainly now into areas where the language to describe the new structures that we are interested in is still lacking.
Question: *Something that I find very intersting as an experiment related to these paradigm shifts, is whether we can teach an LLM concepts from after its training cutoff by explaining them in terms of structures it already reliably knows? For example, can we teach quantum mechanics to an LLM that has only been trained on medieval texts?
The evidence so far suggests models can generalize "downward" in complexity, but not "upward". Meaning we cannot reliably bootstrap a genuinely new conceptual level by composing simpler ones the model has not encountered at that level of abstraction. [5]
The Knowledge Aquisition Process
Despite there being potential inherent limits to what a single LLM can do, we might be able to let multiple agents or systems collaborate together to explore the space outside of the 'knowledge network' of any single LLM
We think about 'all possible statements' outside of the existing 'knowledge network' as describing actors and objects through narratives and rules, without necessarily being grounded in testability.
The role of the Scientific process, and what distinguishes it, is being able to filter out untestable stories, retaining only claims that are: Predictive, Verifiable, and Reproducible in controlled settings.
LLM knowledge generation (letting them generate factual statements) could be very powerful but pre-scientific by default. It might produces plausible relational structures, but not necessarily true ones. [9]
What we would need to add is a validation layer, (similar to the Scientific Process or any other institutionalised epistemic process) that evaluates which generated statements integrate coherently within the existing knowledge network. Either because new statements are empirically verifiable, logically consistent, conceptually coherent, or otherwise useful and meaningful within a given community or context.
Critically, this validation cannot come from the LLM itself: when LLMs attempt to self-correct their own reasoning without external feedback, performance consistently degrades rather than improves. [18] The validation signal must be external and ground-truth-anchored
The Knowledge Harvester
Does that mean we can then build a system that discovers new knowledge (at least in theory, it might be horribly brute-force inefficient in practice):
- Generates all possible knowledge statements at the boundary of LLM's their knowledge space
- Validates them
- Expands the corpus of text outward from validated nodes, incorporating the validated statements
- Trains a new LLM on the resulting corpus
- Repeats the cycle with the new generation of LLMs
This is not purely theoretical. Iterative generate→filter→retrain pipelines have already demonstrated real gains: training models on their own correct reasoning traces, then re-training, nearly doubling performance on mathematical benchmarks. [13] [14]
Would this then be genuinly possible? Or will every model always be bounded by its prior? It seems that such a pipeline faces at least three hard constraints:
Model collapse is real. Training on synthetic outputs causes irreversible loss of distributional diversity and the model's output degrades over successive generations. [16] The fix is to accumulate synthetic and real data together, and to filter synthetic data through a verifier. [17]
The validation step is the bottleneck. The pipeline only works where verification is automated, and reliable. Formal proof checkers, code execution environments, and unit tests provide exactly this — and in those domains, the results have been remarkable. DeepMind's AlphaProof solved three problems at IMO 2024, including one solved by only 5 of 609 human contestants, with every proof machine-verified by Lean. [19] DeepSeek-Prover-V2 achieves 88.9% on the MiniF2F formal mathematics benchmark using a recursive generate-validate-compose pipeline. [20] In domains where truth cannot be mechanically verified, the pipeline has no reliable anchor.
Gains diminish quickly. Most improvement happens in the first one or two iterations, with overfitting setting in around the third. The pipeline is not an open-ended escalator to unlimited knowledge, but a way to extract the knowledge latent at the boundary of what the model already knows.
It is interesting that any LLM based agent will fundamentally be bound by the structure of it's linguistic training data. And at most be able to think only a few steps outside of it (similar to how humans operate within the worldview that the society they grew up in carried around). The evidence suggests this kind of 'Knowledge Harvester' pipeline is possible for new knowledge statements that fall "just outside the boundary" zone (OOD-edge), but fails for knowledge that is truly structurally foreign to the training distribution (OOD-far). [4]
It mght be possible that just how humans can form Academic Institutions, we can create a 'Knowledge Harvester' out of multiple LLMs. Within domains where formal verification is available, something like this is already operational and advancing rapidly for OOD-edge knowledge.
References
- Zhang et al. (ACL 2025).Knowledge Boundary of Large Language Models: A Survey. arXiv:2412.12472Source
- Berglund et al. (ICLR 2024).The Reversal Curse: LLMs Trained on 'A is B' Fail to Learn 'B is A'. arXiv:2309.12288Source
- Bronzini et al. (COLM 2024).Unveiling LLMs: The Evolution of Latent Representations in a Dynamic Knowledge Graph. arXiv:2404.03623Source
- Guo et al. (arXiv 2024).On the Interplay of Pre-Training, Mid-Training, and RL for LLM Reasoning. arXiv:2512.07783Source
- Dziri et al. (NeurIPS 2023).Faith and Fate: Limits of Transformers on Compositionality. arXiv:2305.18654Source
- Webb et al. (Nature Human Behaviour, 2023).Emergent Analogical Reasoning in Large Language Models.Source
- Si et al. (ICLR 2025).Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers. arXiv:2409.04109Source
- McCoy et al. (PNAS, 2024).Embers of Autoregression Show How Large Language Models Are Shaped by the Problem They Are Trained to Solve. arXiv:2309.13638Source
- Banerjee et al. (arXiv, 2024).LLMs Will Always Hallucinate, and We Need to Live With This. arXiv:2409.05746Source
- Orgad et al. (arXiv, 2024).LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations. arXiv:2410.02707Source
- Kapoor et al. (NeurIPS 2024).Large Language Models Must Be Taught to Know What They Don't Know.Source
- Hosseini et al. (COLM 2024).V-STaR: Training Verifiers for Self-Taught Reasoners. arXiv:2402.06457Source
- Romera-Paredes et al. (Nature, 2024).Mathematical Discoveries from Program Search with Large Language Models (FunSearch).Source
- Shumailov et al. (Nature, 2024).AI Models Collapse When Trained on Recursively Generated Data.Source
- Feng et al. (ICLR 2025).Beyond Model Collapse: Scaling Up with Synthesized Data Requires Verification. arXiv:2406.07515Source
- Huang et al. (ICLR 2024).Large Language Models Cannot Self-Correct Reasoning Yet. arXiv:2310.01798Source
- Hubert et al. / DeepMind (Nature, 2025).Olympiad-Level Formal Mathematical Reasoning with Reinforcement Learning (AlphaProof).Source
- Ren et al. (arXiv, 2025).DeepSeek-Prover-V2: Advancing Formal Mathematical Reasoning via Reinforcement Learning for Subgoal Decomposition. arXiv:2504.21801Source